![]()
Welcome to Galaxy for Microbiome
Galaxy for Microbiome (ASaiM) is a webserver to process, analyse and visualize microbiome data in general. It is based on the Galaxy framework, which guarantees simple access, easy extension, flexible adaption to personal and security needs, and sophisticated analyses independent of command-line knowledge.
Content
Get started
Are you new to Galaxy, or returning after a long time, and looking for help to get started? Take a guided tour through Galaxy’s user interface.
Training
We are working in close collaboration with the Galaxy Training Network (GTN) to develop training materials of data analyses based on Galaxy. If you want to know more about the GTN or how to become part of the Galaxy community, check the videos below!
Training material
All relevant materials for microbiome data analysis can also be found within the GTN.
| Lesson | Slides | Hands-on | Input dataset | Workflows | Galaxy History |
|---|---|---|---|---|---|
| Welcome and introduction to Galaxy | / | ||||
| An Introduction to Metagenomics | |||||
| Quality Control | / | / | |||
| 16S Microbial Analysis with mothur | Short / Extended / | ||||
| 16S Microbial analysis with Nanopore data | |||||
| Analyses of metagenomics data - The global picture | |||||
| Metatranscriptomics analysis using microbiome RNA-seq data | Short / Extended | ||||
| Metaproteomics introduction | / |
Tools
More than 200 tools are avalaible for microbiome data analysis in this custom Galaxy instance:
- General tools
- Data retrieval: EBISearch, ENASearch, SRA Tools
- BAM/SAM file manipulation: SAM tools
- BIOM file manipulation: BIOM-Format tools
- Genomics tools
- Quality control: FastQC, PRINSEQ, Cutadapt, fastp, Trimmomatic, MultiQC
- Clustering: CD-Hit
- Sorting and prediction: SortMeRNA, FragGeneScan
- Mapping: BWA, Bowtie
- Similarity search: NCBI Blast+, Diamond
- Alignment: HMMER3
- Microbiota dedicated tools
- Microbial: Scoary, Prokka, Roary
- Metagenomics data manipulation: VSearch, Nonpareil, DADA2
- Assembly: MEGAHIT, metaSPAdes, metaQUAST, VALET, Bandage, MaxBin2
- Metataxonomic sequence analysis: Mothur, QIIME, Vegan
- Taxonomy assignation: MetaPhlAn, Kraken, CAT/BAT
- Metabolism assignation: HUMAnN, PICRUST, InterProScan
- Visualization: Export2graphlan, GraPhlAn, KRONA
- Metaproteomics: MaxQuant, SearchGUI, PeptideShaker, Unipept
Workflows
To orchestrate tools and help users with their analyses, several workflows are available. They formally orchestrate tools in a defined order and with defined parameters, but they are customizable (tools, order, parameters).
The workflows are available in the Shared Workflows, with the label “asaim”.
Taxonomic and functional community profiling of raw metagenomic shotgun data
The workflow quickly produces, from raw metagenomic shotgun data, accurate and precise taxonomic assignations, wide extended functional results and taxonomically related metabolism information
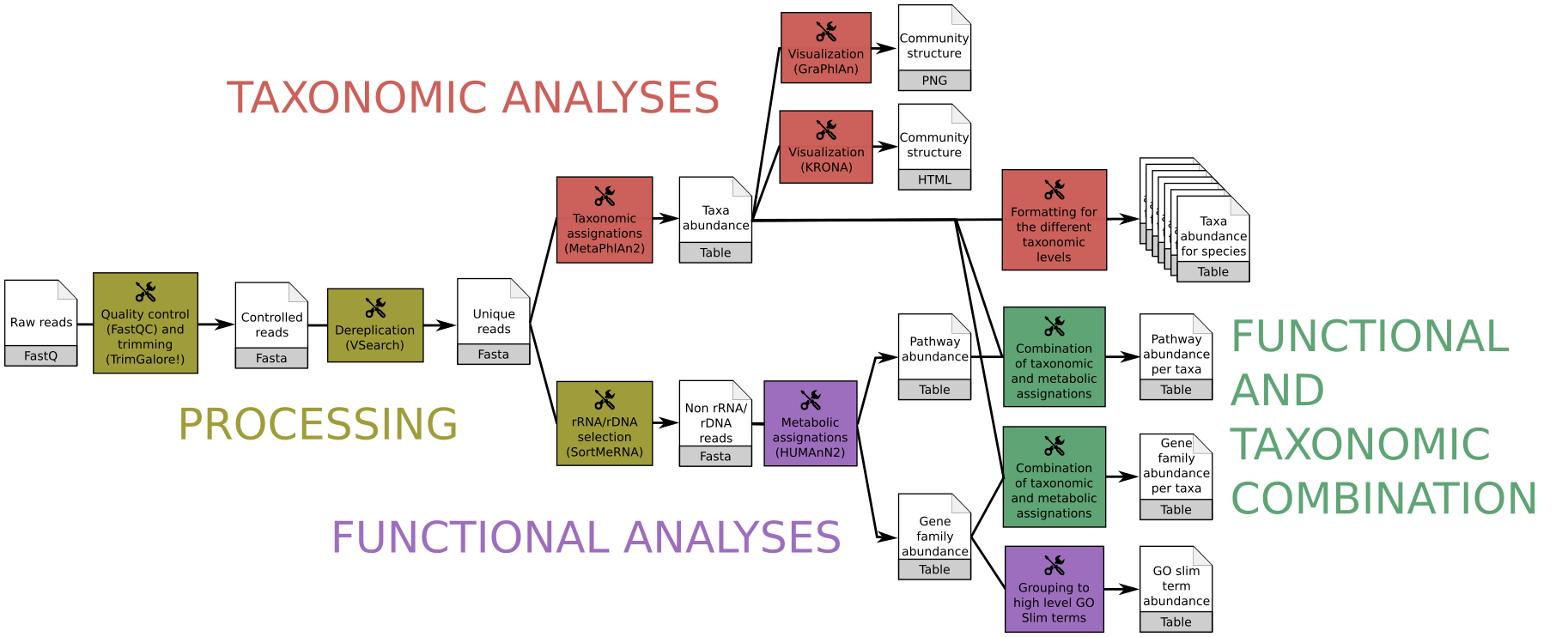
This workflow consists of
- Processing with quality control/trimming (FastQC and Trim Galore!) and dereplication (VSearch)
- Taxonomic analyses with assignation (MetaPhlAn2) and visualization (KRONA, GraPhlAn)
- Functional analyses with metabolic assignation and pathway reconstruction (HUMAnN2)
- Functional and taxonomic combination with developed tools combining HUMAnN2 and MetaPhlAn2 outputs
It is available with 4 versions, given the input
- Simple files: Single-end or paired-end
- Collection input files: Single-end or paired-end
Assembly of metagenomic data
To reconstruct genomes or to get longer sequences for further analysis, microbiota data needs to be assembled, using the recently developed metagenomics assemblers.
To help in this task, two workflows have been developed using two different well-performing assemblers:
-
It is currently the most efficent computationally assembler: it has the lowest memory and time consumption (van der Walt et al., 2017; Awad et al., 2017; Sczyrba et al., 2017). It produced some of the best assemblies (irrespective of sequencing coverage) with the fewest structural errors (Olson et al., 2017) and outperforms in recovering the genomes of closely related strains (Awad et al., 2017), but has a bias towards relatively low coverage genomes leading to a suboptimal assembly of high abundant community member genomes in very large datasets (Vollmers et al., 2017)
-
It is particularly optimal for high-coverage metagenomes (van der Walt et al., 2017) with the best contig metrics (Greenwald et al., 2017) and produces few under-collapsed/over-collapsed repeats (Olson et al., 2017)
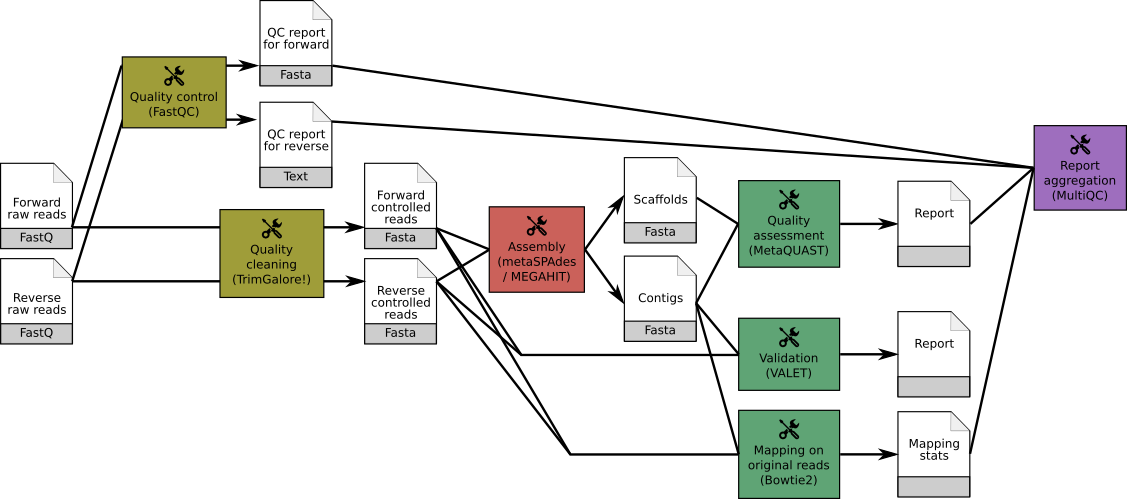
Both workflows consists of
- Processing with quality control/trimming (FastQC and Trim Galore!)
- Assembly with either MEGAHIT or MetaSPAdes
- Estimation of the assembly quality statistics with MetaQUAST
- Identification of potential assembly error signature with VALET
- Determination of percentage of unmapped reads with Bowtie2 combined with MultiQC to aggregate the results.
Analysis of metataxonomic data
To analyze amplicon data, the Mothur and QIIME tool suites are available there. We implemented the workflows described in tutorials of Mothur and QIIME websites, as example of amplicon data analyses as well as support for the training material. These workflows, as any workflows available there, can be adapted for a specific analysis or used as subworkflows by the users.
ASaiM-MT: Optimized workflow for metatranscriptomics data analysis
While the shotgun workflow is suitable for both metagenomics and metatranscriptomics datasets, we also offer an enhanced workflow aimed specifically at metatranscriptomics data.
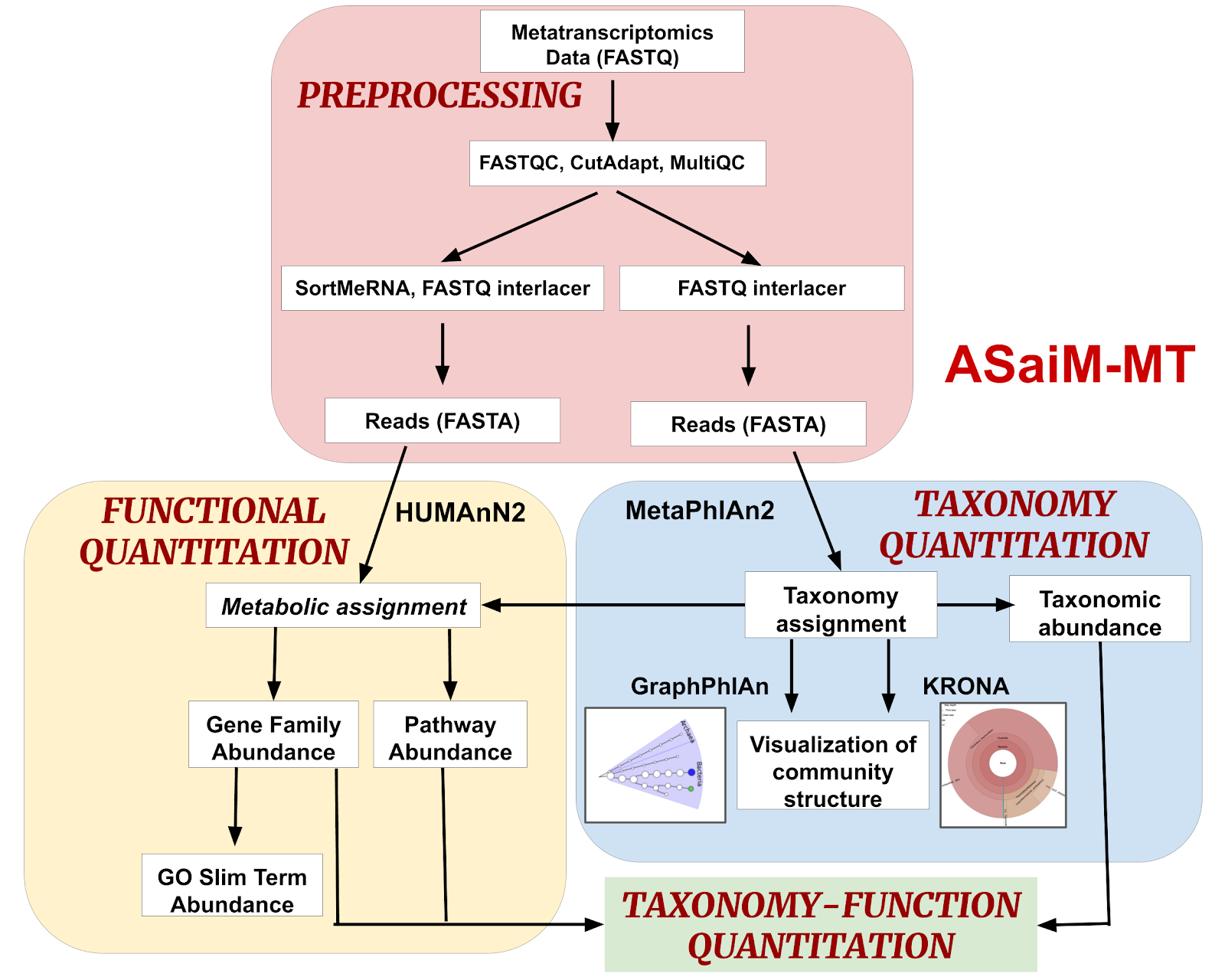
The workflow is divided into 4 parts:
- Preprocessing - Process raw metatranscriptomics data to perform further analysis.
- Taxonomy Quantitation - Assignment of taxonomy along with abundance values and visualization.
- Functional Quantitation - metabolic assignment of identified functions and gene and pathway abundance annotation.
- Taxonomy-Function Quantitation - combine taxonomy and functional quantitation values into relative abundance values at different levels such as e.g. the abundance of a pathway between phyla.
Integrative meta-omics analysis - Metagenomics, Metatranscriptomics, Metaproteomics
The combination of metagenomics, -transcriptomics and -proteomics can provide a detailed understanding of which organisms occupy specific metabolic niches, how they interact, and how they utilize environmental nutrients. Commonly used omics tools spanning metagenomics, -transcriptomics and -proteomics has been adapted into an integrated meta-omics analysis pipeline:
-
Metagenomics
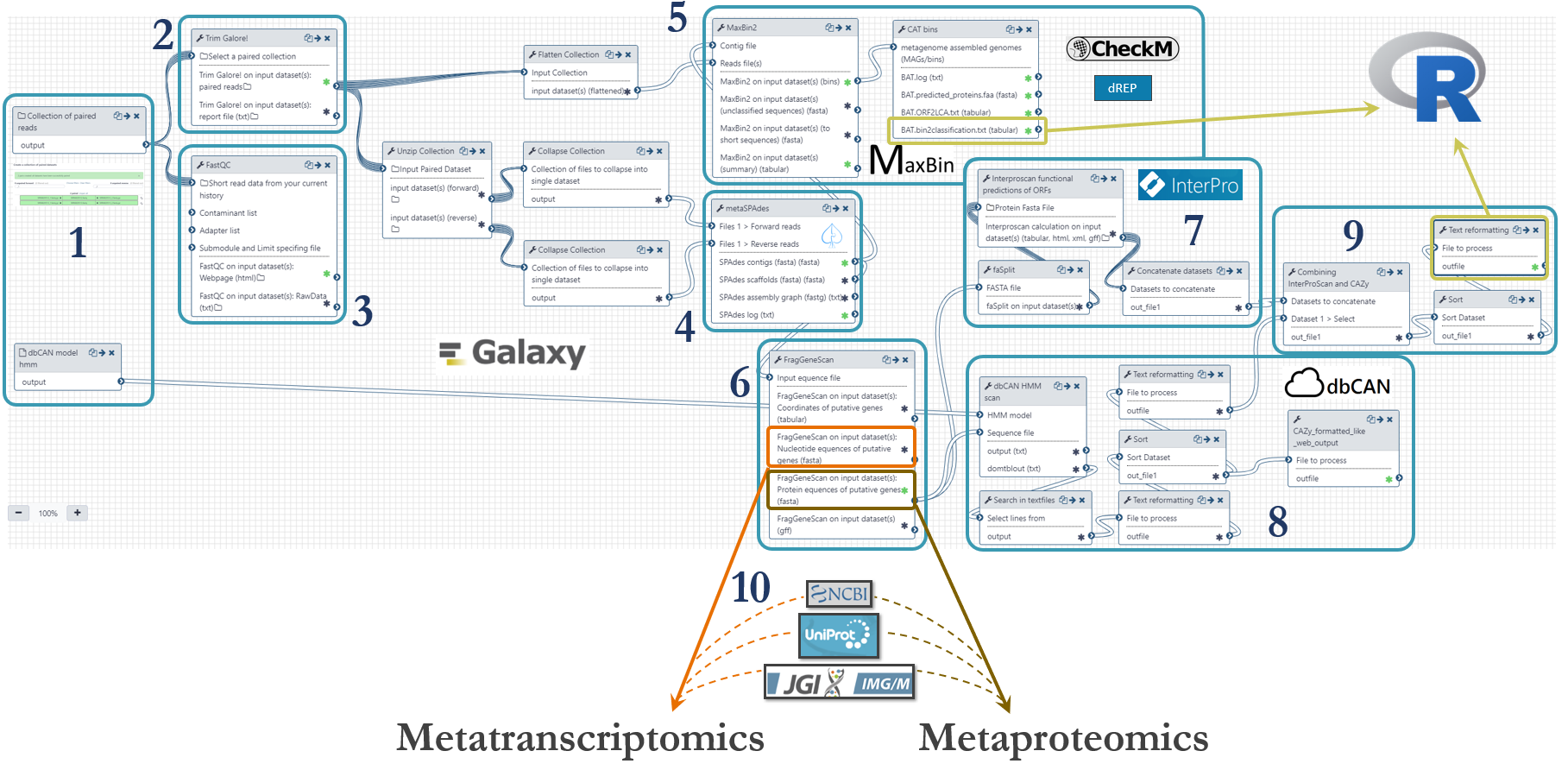
-
Metatranscriptomics
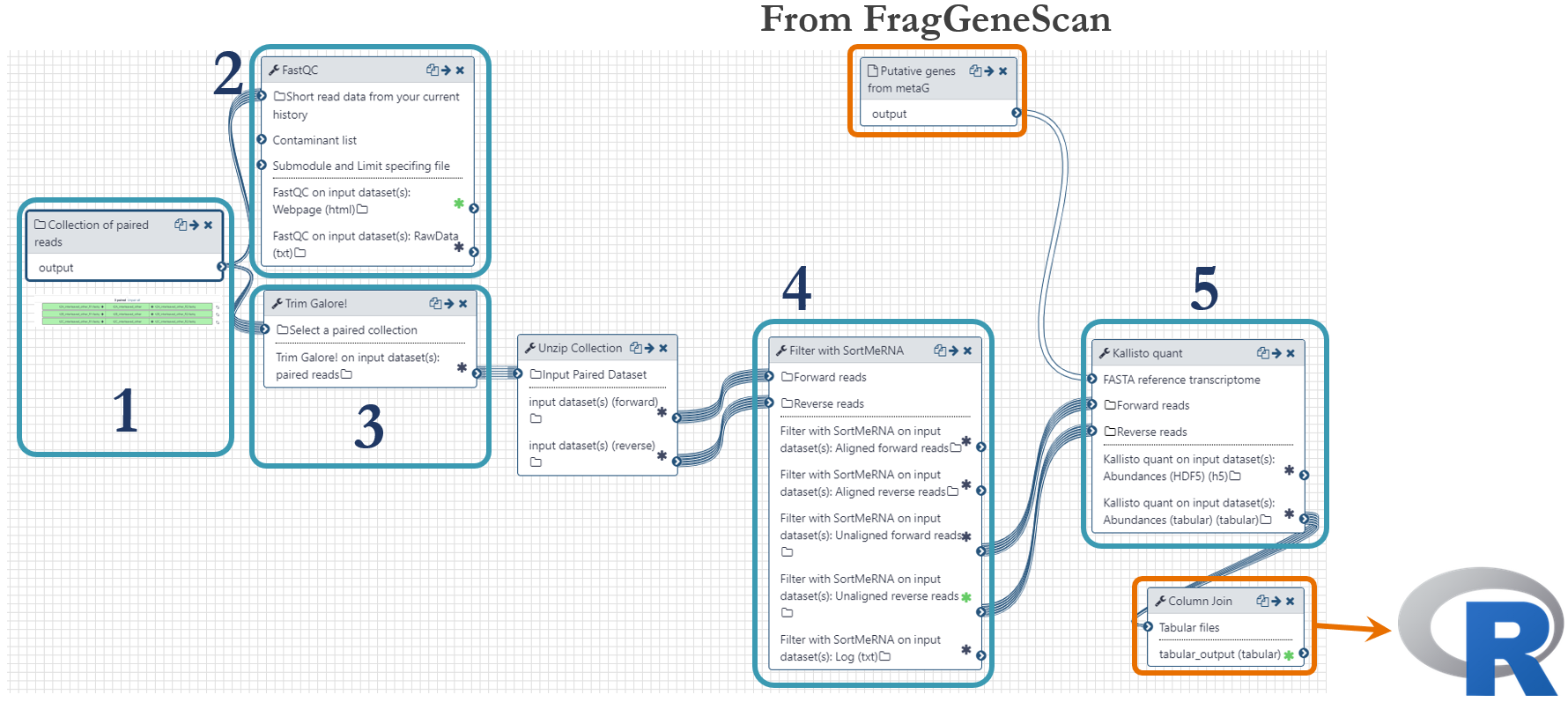
-
Metaproteomics
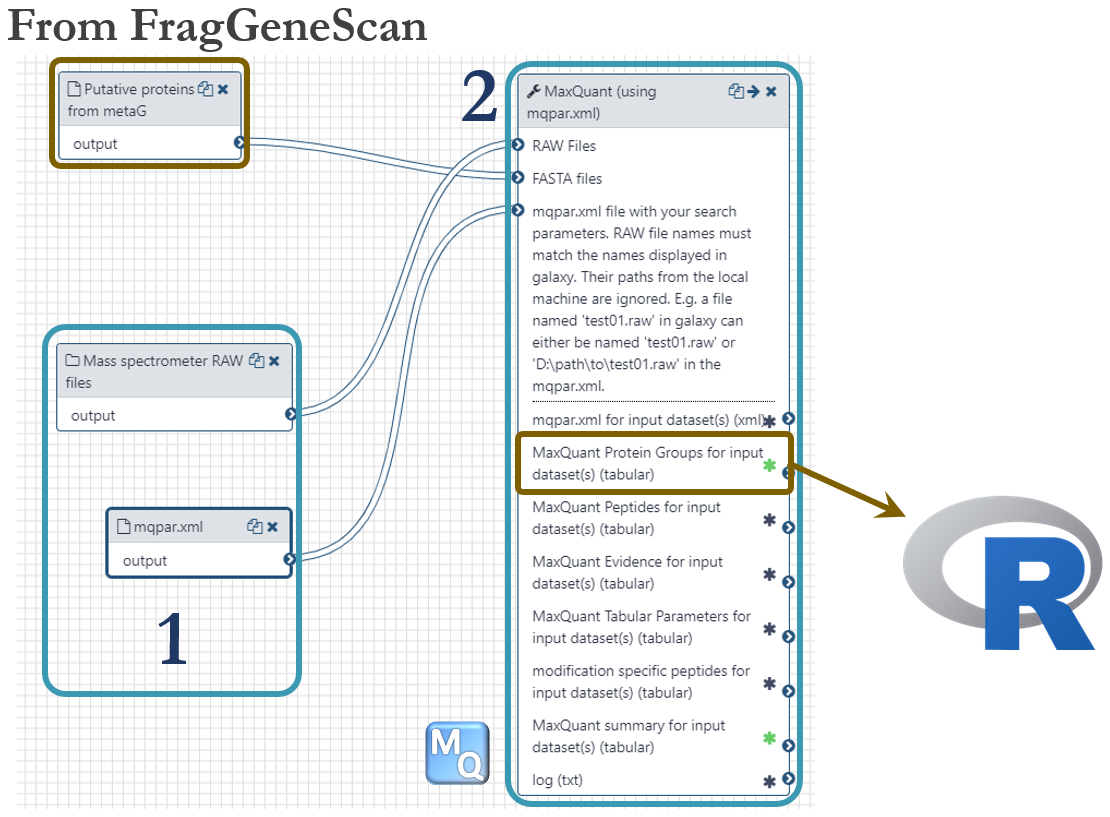
-
Integration of omics data using R
This pipeline has been applied to deconvolute a highly efficient cellulose-degrading minimal consortium isolated and enriched from a biogas reactor in Fredrikstad, Norway
References
- Awad,S. et al. (2017) Evaluating Metagenome Assembly on a Simple Defined Community with Many Strain Variants. bioRxiv, 155358.
- Greenwald,W.W. et al. (2017) Utilization of defined microbial communities enables effective evaluation of meta-genomic assemblies. BMC genomics, 18, 296.
- Olson,N.D. et al. (2017) Metagenomic assembly through the lens of validation: recent advances in assessing and improving the quality of genomes assembled from metagenomes. Briefings in Bioinformatics, bbx098.
- Sczyrba,A. et al. (2017) Critical Assessment of Metagenome Interpretation- a benchmark of computational metagenomics software. Biorxiv, 099127.
- Walt,A.J. van der et al. (2017) Assembling metagenomes, one community at a time. bioRxiv, 120154.
- Vollmers,J. et al. (2017) Comparing and Evaluating Metagenome Assembly Tools from a Microbiologist’s Perspective-Not Only Size Matters! PloS one, 12, e0169662.
Our Data Policy
| Registered Users | Unregistered Users | FTP Data | GDPR Compliance |
|---|---|---|---|
| User data on UseGalaxy.eu (i.e. datasets, histories) will be available as long as they are not deleted by the user. Once marked as deleted the datasets will be permanently removed within 14 days. If the user "purges" the dataset in the Galaxy, it will be removed immediately, permanently. An extended quota can be requested for a limited time period in special cases. | Processed data will only be accessible during one browser session, using a cookie to identify your data. This cookie is not used for any other purposes (e.g. tracking or analytics). If UseGalaxy.eu service is not accessed for 90 days, those datasets will be permanently deleted. | Any user data uploaded to our FTP server should be imported into Galaxy as soon as possible. Data left in FTP folders for more than 3 months, will be deleted. | The Galaxy service complies with the EU General Data Protection Regulation (GDPR). You can read more about this on our Terms and Conditions. |