We have been experimentally running some Galaxy jobs in the bwCloud at the University of Freiburg. Unlike more traditional compute resources we can scale the cloud resources up and down on-demand.
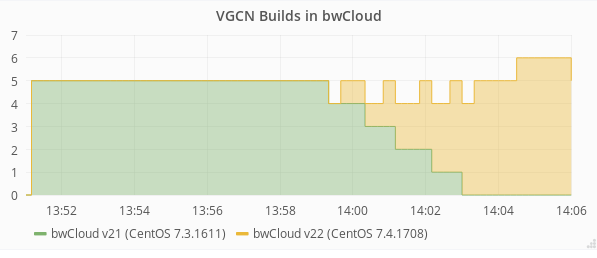
But what happens when we need to replace the VMs? We built a new version of our compute node images but we didn’t want to disrupt jobs that were running.
So we spent some time developing a small tool to gracefully terminate the VMs running the old image and replace them with VMs running the new image.
The software is freely available under the GPL license