New Paper "Democratizing data-independent acquisition proteomics analysis on public cloud infrastructures via the Galaxy framework"
Matthias Fahrner from the University of Freiburg is defending his PhD today. Read his latest work about data-independent acquisition (DIA) of mass spectrometric proteomic studies in the paper published two weeks ago. Congratulations Dr. Matthias :)
Abstract - Background Data-independent acquisition (DIA) has become an important approach in global, mass spectrometric proteomic studies because it provides in-depth insights into the molecular variety of biological systems. However, DIA data analysis remains challenging owing to the high complexity and large data and sample size, which require specialized software and vast computing infrastructures. Most available open-source DIA software necessitates basic programming skills and covers only a fraction of a complete DIA data analysis. In consequence, DIA data analysis often requires usage of multiple software tools and compatibility thereof, severely limiting the usability and reproducibility.
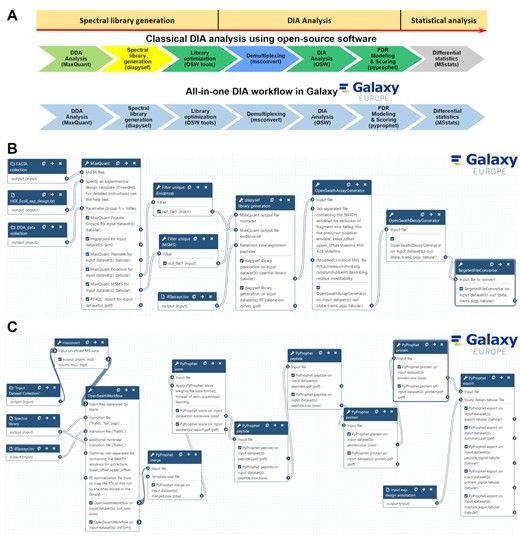
Findings To overcome this hurdle, we have integrated a suite of open-source DIA tools in the Galaxy framework for reproducible and version-controlled data processing. The DIA suite includes OpenSwath, PyProphet, diapysef, and swath2stats. We have compiled functional Galaxy pipelines for DIA processing, which provide a web-based graphical user interface to these pre-installed and pre-configured tools for their use on freely accessible, powerful computational resources of the Galaxy framework. This approach also enables seamless sharing workflows with full configuration in addition to sharing raw data and results. We demonstrate the usability of an all-in-one DIA pipeline in Galaxy by the analysis of a spike-in case study dataset. Additionally, extensive training material is provided to further increase access for the proteomics community.
Conclusion The integration of an open-source DIA analysis suite in the web-based and user-friendly Galaxy framework in combination with extensive training material empowers a broad community of researches to perform reproducible and transparent DIA data analysis.